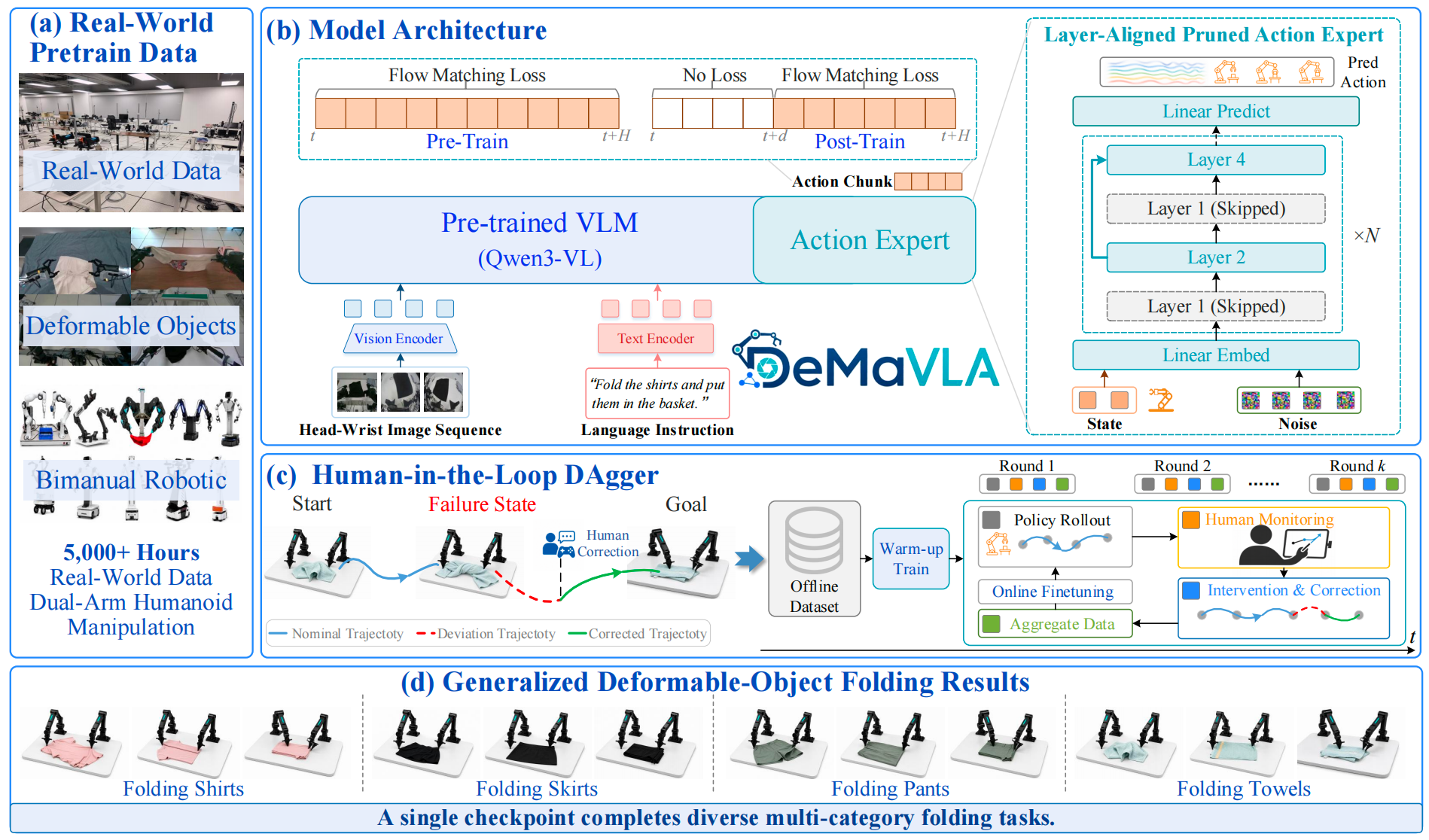
The DeMaVLA Model
DeMaVLA is trained from real-world dual-arm demonstrations and integrates a Qwen3-VL backbone, a layer-aligned pruned action expert, flow-matching action generation, training-time RTC for asynchronous execution, and human-in-the-loop DAgger for corrective real-world learning. A single checkpoint is used to perform diverse multi-category folding tasks.
Simulation Results
To comprehensively evaluate DeMaVLA, we conduct experiments on the RoboTwin simulation benchmark, which contains 50 bimanual manipulation tasks under both clean and randomized settings. The clean setting uses fixed initial configurations, while the randomized setting varies object poses and scene layouts. As shown in the following table, DeMaVLA achieves the best average performance under both settings.

Real-world Results
We further evaluate DeMaVLA on a real-world household folding benchmark using an ALOHA-style dual-arm robot. The benchmark contains four representative folding tasks: folding a shirt, folding a skirt, folding pants, and folding a towel. As shown in the following table, DeMaVLA achieves a higher average SR than pi0 across the four tasks, improving from 76.3% to 92.5%. These results indicate that DeMaVLA can share folding priors across garment categories and execute them through a single multi-task policy.
